posted under category: Software Quality on March 2, 2019 by Nathan
People don’t like to talk about real standards for commenting your code. They give you abstract thoughts and ideas, then back up and say just do what your team decides to do. Certainly consistency is important, but what if you are consistently bad? This is why I like Code Complete by Steve McConnell. Steve lays down hard figures. You may not agree with him, but he will get you to form an opinion, even if it’s contrary. So in the same spirit, let me talk about what I think you should comment.
First off, I want to remind you that comments are at a different level than the code. As Code Complete says: “Good comments don’t repeat the code or explain it. They clarify its intent. Comments should explain, at a higher level of abstraction than the code, what you’re trying to do.”
-
Comment every code file
Classes should describe what they are, as simply as possible. View templates should explain their purpose. I think commenting directories with a readme is also nice.
-
Comment every method
Preferably, comment your methods within a metadata block that can be used to generate documentation for you later, if your platform supports it.
-
Comment to describe ambiguous variables or acronyms
Typically these may be endline comments on the variable declaration to avoid confusion.
-
Comment on blocks of code
Again, comments should be on a higher level, and should not detail /how/ a block of code works, but should explain why a block of code is here and what its purpose is.
-
Comment surprises
Point out when you are doing something non-standard, or something particularly clever that may be hard to follow.
What do you think? Not enough or too much? What am I missing?
When Not to Comment Code
Almost as important as when to comment, is the inverse.
- For starters, don’t comment if you don’t have anything to add. Don’t comment just because you don’t see enough comments in the code you are looking at.
- Don’t comment if you don’t understand the context and the intent. Your comment will just be inaccurate.
- Don’t comment to explain every variable. Not unless it’s really necessary.
- Never comment a file change history. That’s what source control software (like Git) is for.
- Don’t comment descriptions on obvious variables.
User_Name; // This is the user name
I, Nathan Strutz, IT and computing professional for over two decades and senior level programmer at the world’s best aerospace company, being of sound mind, fully deputize you with the rights, the permission, and the duty to delete comments that match these parameters. The world will be a better place when these useless code comments are gone.
(Discuss with Disqus!)
posted under category: Life Events on February 28, 2019 by Nathan
I mentioned a couple weeks ago that I was working on updating my blog tooling to make it friendlier for me to use. Well I’ve gone and done a couple of interesting things.
- I added support for markdown
It’s like no software these days is complete until it supports markdown files. Vue CLI UI makes it pretty easy to add NPM packages. Actually, I prefer that method over the command line now because I lose the fear of misspelling the name of a package or install the wrong one because it has a logical name, and it always tells me when a package is out of date. I really love Vue UI! If you’re not convinced yet then I’ll tell you it has a dark mode. You’re welcome.
I chose the cleverly-named vue-markdown package. Okay, maybe that’s not such a clever name, but I don’t need clever, I need a markdown library that works with Vue and is easy to use, easy to integrate, and lets me work the way I want. Vue-markdown succeeds on all fronts. It’s as easy as:
<vue-markdown @rendered="grabMarkdown" :linkify="false">{{post.bodyMarkdown}}</vue-markdown>
I had to fight with it a bit in order to get both the markdown text as well as the rendered HTML - one for my continued editing, and the other for outputting on the screen without forcing a markdown render on your web browser as you read this. Because the markdown is only rendering as HTML when my editor is on the preview tab, I have to force the tabs to switch over to the preview (if it’s not already there) so that there is HTML that I can save. Of course it takes a moment to do that, it’s not automatic. Vue’s $nextTick() comes in handy in these types of situations, even though every time I use it, it feels like a hack. Really it’s just a sign that I’m rushing through a solution without thinking fully through it. Then again on the other hand, my React project at work could really use a nextTick method - setting a short timeout to an anonymous function is even more of a hack.
Anyway, Markdown was an easy thing to add, and anything that gets me playing with Vue more is a sure positive.
- Friendlier blog post URLs
I always think of URLs as part of the UX. A well-thought-out address should be discoverable and simple. It’s not even for the SEO, although I bet it benefits as well. It’s really just a thoughtful way to care for my visitors.
My post scheme is easy - this one will be /techblog/388 but is also addressable by the name alone /techblog/post/Continuing-the-blog-upkeep. That second one (slug-only links) will probably be an unused feature, but I like the idea that the ID isn’t required as part of the URL because it seems cleaner.
The worst part of the friendly URL change was definitely the URL rewriting. Not because it’s difficult, no way, but because there are so many ways to do it, and it’s hard to find the right one. For example, Hostek, my wonderful web site host that I definitely recommend, says they recommend using a .htaccess file, and that it works with ISAPI_Rewrite. I didn’t have any luck with that. The file would have been this:
.htaccess
RewriteEngine On
RewriteBase /
RewriteRule ^techblog/([0-9]+)/?(.*)$ /techblog/?id=$1 [NC,L]
RewriteRule ^techblog/(post|entry|slug)/([a-zA-Z0-9_-]+)$ /techblog/index.cfm?slug=$2 [NC,L]
Instead, I had much better luck using a web.config file. Clearly I’m on an IIS server. This worked, but the backreferencing is so ugly. Only Microsoft could ruin regular expressions. That file is like this:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<system.webServer>
<rewrite>
<rules>
<rule name="Blog Post Slugs">
<match url="^techblog/(post|entry|slug)/([a-zA-Z0-9_-]+)$" />
<action type="Rewrite" url="techblog/index.cfm?slug={R:2}" />
</rule>
<rule name="Blog Post IDs">
<match url="^techblog/([0-9]+)/?(.*)$" />
<action type="Rewrite" url="techblog/index.cfm?id={R:1}" />
</rule>
</rules>
</rewrite>
</system.webServer>
</configuration>
Finally, I also have this site running locally in a Lucee server. It’s fast and minimal and I love it, but it’s Tomcat/Catalina which is a little harder to google the solution. The redirect file is called rewrite.config and it lives in my lucee\tomcat\conf\Catalina{domain}\ folder. It looks like this:
RewriteRule ^/techblog/([0-9]+)/?(.*)$ /techblog/?id=$1 [NC,L]
RewriteRule ^/techblog/(post|entry|slug)/([a-zA-Z0-9_-]+)$ /techblog/index.cfm?slug=$2 [NC,L]
There are subtle differences between all of these, and that was my biggest pain point.
Anyways, I hope this has been entertaining and educational as I continue to evolve dopefly.com into something that makes me proud to be associated with.
Coming up next: Fonts and colors for rendering code. Friendly URLs for years and categories. Those are the small plans that are definitely happening. The big plans are things like dumping the database altogether, putting all the code on GitHub, continuous deployment from commits, and other things I’ll probably never get to.
(Discuss with Disqus!)
posted under category: Software Quality on February 21, 2019 by Nathan
Five years ago, my friend Shawn and I began a discussion on documentation. He was new to my project, we’ll call it Rhubarb 2000, and bemoaned the lack of documentation. I hadn’t document enough for my new developer, and I’m guilty of charging this technical debt that my friend had to pay interest on.
So we asked the question: How much documentation is enough? It sat on our whiteboard for weeks. We would talk about it in the afternoons, but accomplish nothing. Eventually, we came up with a number of ways to answer the question.
So, what do you think? Given the transition of an application between two developers in the win-the-lottery scenario (also called the hit-by-a-bus scenario, but let’s think positively), what is the right amount of documentation to have?
The first successful attack at the question we had was to break it down to two atomic categories: failure and success. Failure meaning it was not a successful transition; the new developer had trouble understanding the new system and grew to loathe it because it didn’t make sense. Success meaning the transition was successful; the old developer did not need to be contacted and the new developer experienced minimal trouble understanding the what-where-when-why-how’s of the new system because the available documentation was sufficient.
This black and white view was good way to answer the question - we want transitions to be painless. More than that, we want it to be stress free for our imaginary future friend. Many companies don’t have a minimal amount of documentation. My company’s minimal documentation standards are just some boilerplate stuff about processes, which do nothing to qualify for a stress free transition.
Eventually we came to a better, multi-tiered answer. It’s simple. There are five levels taken from elementary grading or performance management that we can judge ourselves on: Does Not Meet, Meets Some, Meets, Exceeds, and Far Exceeds. This way, we can set our own metrics on meeting the expected documentation. It’s a framework for judging amounts of documentation that anyone can play.
Another parallel scale we came up with to sub-classify documentation was: no documentation, disorganized or minimal, organized, and polished. This judges the existing documentation on a scale of bad to good. All together, I think it looks like this.

Minimum Viable Documentation
Let’s say we’re doing our jobs pretty well, and we create at least the amount of documentation that we are required to. That leaves us with some process required deliverables and an entry into the company’s applications database. These are pretty much the required bare minimums, which I call Minimum Viable Documentation.
By creating just the required documentation, we may be meeting the lowest bar, but any future transition (when I win the lottery and retire), is going to be just awful for the person who replaces me. Of course it’s only fair to reverse it and say if someone else wins the lottery (it’s always someone else, isn’t it?), then how much documentation do you hope they have? Personally I hope it’s a lot more than process templates and a record in a database.
Just outside of the minimum, yet still in the category of not meeting expectations, you may find historical requirements and a change log. It’s nice to have these things, and our projects and products really need to have this kind of information, but again, if someone handed it to me, it would not be a very successful transition.
Even apart from winning the lottery, lets say our project grows and the business decides to grant us with more developers next year. Our new helpers should be able to hit the ground running. If we’ve been skating by with the minimum because that’s all we needed, then we have failed our new teammates and need to catch up.
Simply Not Enough Documentation
On our scale of documentation, far to the left, we have the default, which is essentially the equivalent of no actual documentation. We’ve probably all been handed systems like this - heaven knows I sure have. Then again, in my pre-Boeing days, I’ve even created a couple – SHHH don’t tell!
The worst amount of documentation we can provide for any system in a developer hand-off is pretty much just the code. And unfortunately, it’s completely possible that many of us have --done-- seen this. If we were able to “accept no defects,” then we would just say “no thank-you.” Unfortunately however, we’re programmers living in the real world, and we don’t get to say “no” very often.
Enough Documentation to Win the Lottery
Surely some amount of documentation has to be enough to make a transition successful. For an active application, in order to hand off your work to someone else and move to an exotic beach island, what amount of documentation do you need to have already written?
An official transition may have us fill out some kind of information packet. The new developer needs all the file paths, various accounts, and server names. If there is an API, there should be documentation on it somewhere that they can find. This is where every automatic self-documenting tool will help, from Javadocs to Swagger, bring out those links.
Along with API documentation, our new developer needs to see the build and release process - whatever that looks like. For Rhubarb 2000, there is a small resource compile step in an Ant build file, some Git management, then batch files to push various branches to dev and test environments, followed by the overly-complex production release process that we have, you’ll be thankful I’m not going into it. That all needs to be written down somewhere. In addition to this, it will help to have some kind of guide to setting up an appropriate developer workstation - do I need a VM, what web server do I install, etc.
Any new developer must be able to run the unit test suite (and really, you should have some tests, really). That’s the success point on the technical transition - the developer can successfully execute the unit testing suite.
Once our new developer has all of those essentials, bring them into the project. Every application has some kind of ticketing workflow, sometimes as simple as emails, sometimes as complicated as Jira. Introduce them to it and explain how it works. Then introduce them to the operating rhythm. This is especially important for agile projects - if we do work in 3 week sprints, lay out the sprint and meeting schedule for them.
Also to note that at this stage of documentation maturity, we should have some form of organization for this documentation. It should be pretty easily discoverable by anyone who joins the project. For me, that means my project has a readme file with the code that points to the GitLab wiki and our Sharepoint site. Likewise, the GitLab wiki points to the Sharepoint, and the Sharepoint points to the GitLab wiki. It’s circular because we want new people to know that they’re in the right place.
After all of that, you can win the lottery or bring in a new hire and expect them to do pretty well, at least as far as the project goes.
Enough Documentation to Really Succeed
So let’s say we have a successful transition, and everything is in line for our new protégé to get going with the project. What’s next? What more could we do to nudge them into the pit of success? This could be more documentation than we really need, but not more than we should have. It’s above the average, and at least meeting some of these gets a thumbs-up in my book.
If we have software diagrams, that’s really helping the next developer. These are possibly the best thing we can pass on. Describing my mental model of the application using images passes on the real thoughts I have about it - my visual comprehension and perception of the application. Objects depicted as boxes and circles can be infinitely valuable later on. Consider the aspects of software that can be diagrammed - object models, big transaction areas where a lot of work is done, how we use MVC, how our services are wired together, usage of IoC containers, and how our data persistence works.
What if we create a physical architecture diagram with servers and developers and source control? That’s really getting there. Perhaps this is a handful of diagrams, one for each system we’re connected with, or one for each environment, or one for each contextual way to think about the application. Maybe we should just have one huge image of all the servers and systems and how they connect.
A database diagram would also be helpful. Some of these can be generated, especially when there are a lot of foreign key constraints, but that isn’t always the case, so try to draw the lines between columns and tables. This should point out the most central aspects of the application and give our new developer an idea of where to look for dangerous areas. As long as the data diagrams aren’t too large, I’ve seen this used a lot for field name lookups.
If we want new developers to keep up with the standards that the team has set, then write a style guide. Write one for code. Write one for visual design. Write one for standard patterns that should be used. I thought much of my work was obvious with the direction I was taking, but it turns out it was naïve of me to expect it without writing it all down.
The last thing for really succeeding is to have features documented for your users, not just your developers. Tailored documentation is helpful here, perhaps one document per role in your system, as well as documents for new features as they’re released. While our customers would love to see this in the Minimum Viable Documentation, realistically user documentation belongs way over here.
That’s my list of good documentation. If you attain this level, you should feel good about yourself.
More than Enough Documentation
Let’s talk stretch goals. What would be the ideal dream for the best possible documentation? This should be your stretch goal. This is what we all wish we could attain, and maybe can with a lot of work. It’s the final level of documentation bliss. Here’s what I mean.
Training screen casts are probably the best way to show new users (and developers) how to use our application. Clearly it’s hard to do a good job and keep this up to date, but those who are dead on selling the system can churn these out, usually only with a marketing budget.
I learned recently that new applications at my company are required to have a usability study. What that means is probably up for interpretation, especially at your company, but it’s good advice. Going above and beyond for your documentation would be to conduct a true study on the system’s usability, and keep it up to date.
Another great thing for documentation would be to have a real case study that explains real world benefits. We’ve got a system here where the team produced a short case study video of how successful they have been, and it’s made the rounds in the executive level, which has been a huge boost for the program.
Another goal at this level is to have a fully automated self-documentation engine that reads the code and keeps itself updated with the latest information about the application. This would be something a couple steps above Javadoc. The great thing about the auto-doc engine is that documentation on your APIs, objects, database tables and so on, are always up to date for you and your team to view.
The last thing I’ll recommend for your stretch goal is a technical writer maintaining all of your documentation. There are numerous benefits, but most notably would be the commonality and organization of all your documents regarding screenshots and writing styles, and also the fact that your documentation would be up to date for as long as they work with you. Keeping your documentation true and up to date is really what your goal is.
Wrapping Up
So you’ve seen my documentation chart. I encourage you to build your own and define what is important to you on your project or portfolio. I’m sure there are gaps and things I haven’t thought about. Why not bring them up in the comments?
(Discuss with Disqus!)
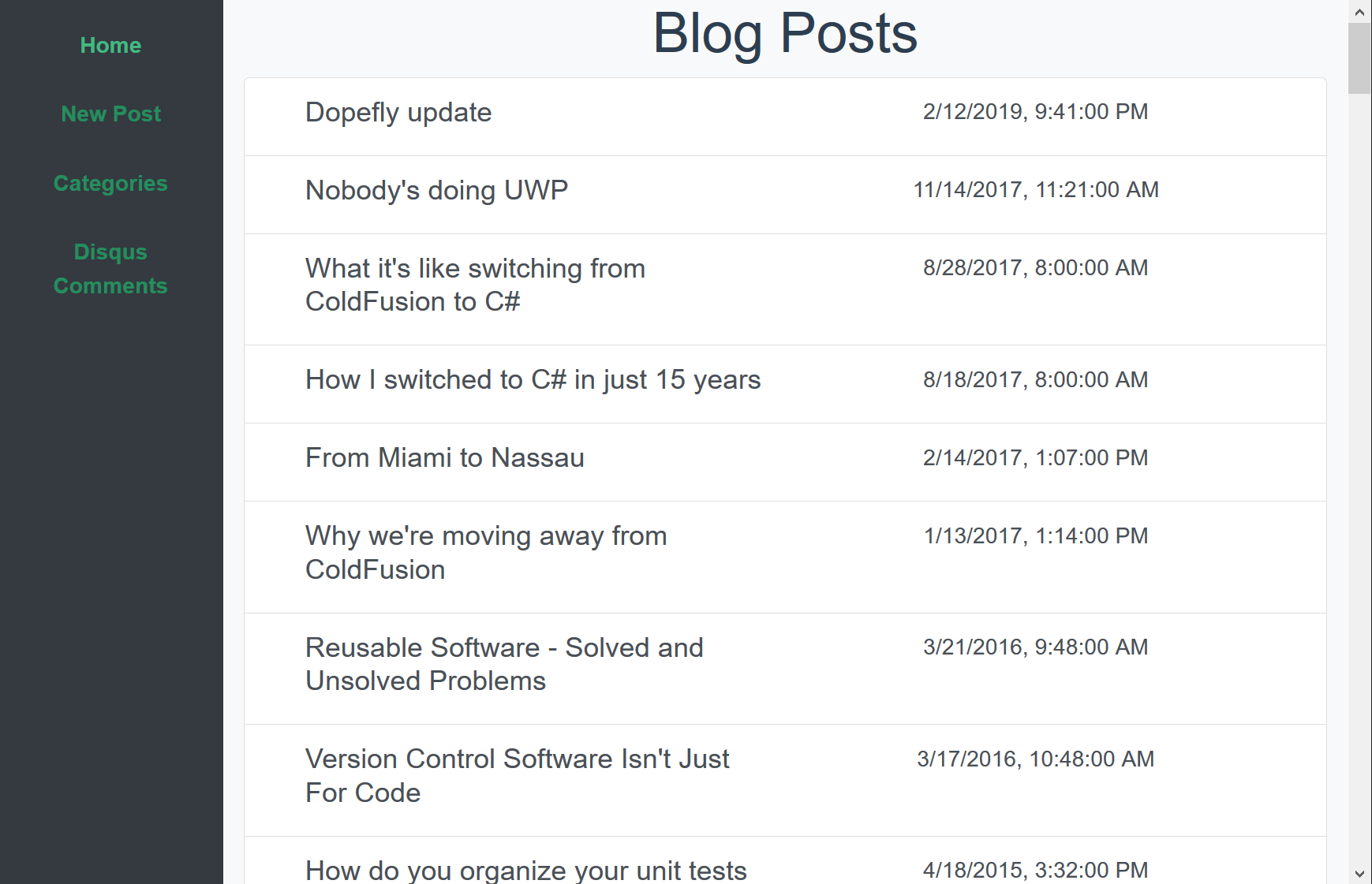
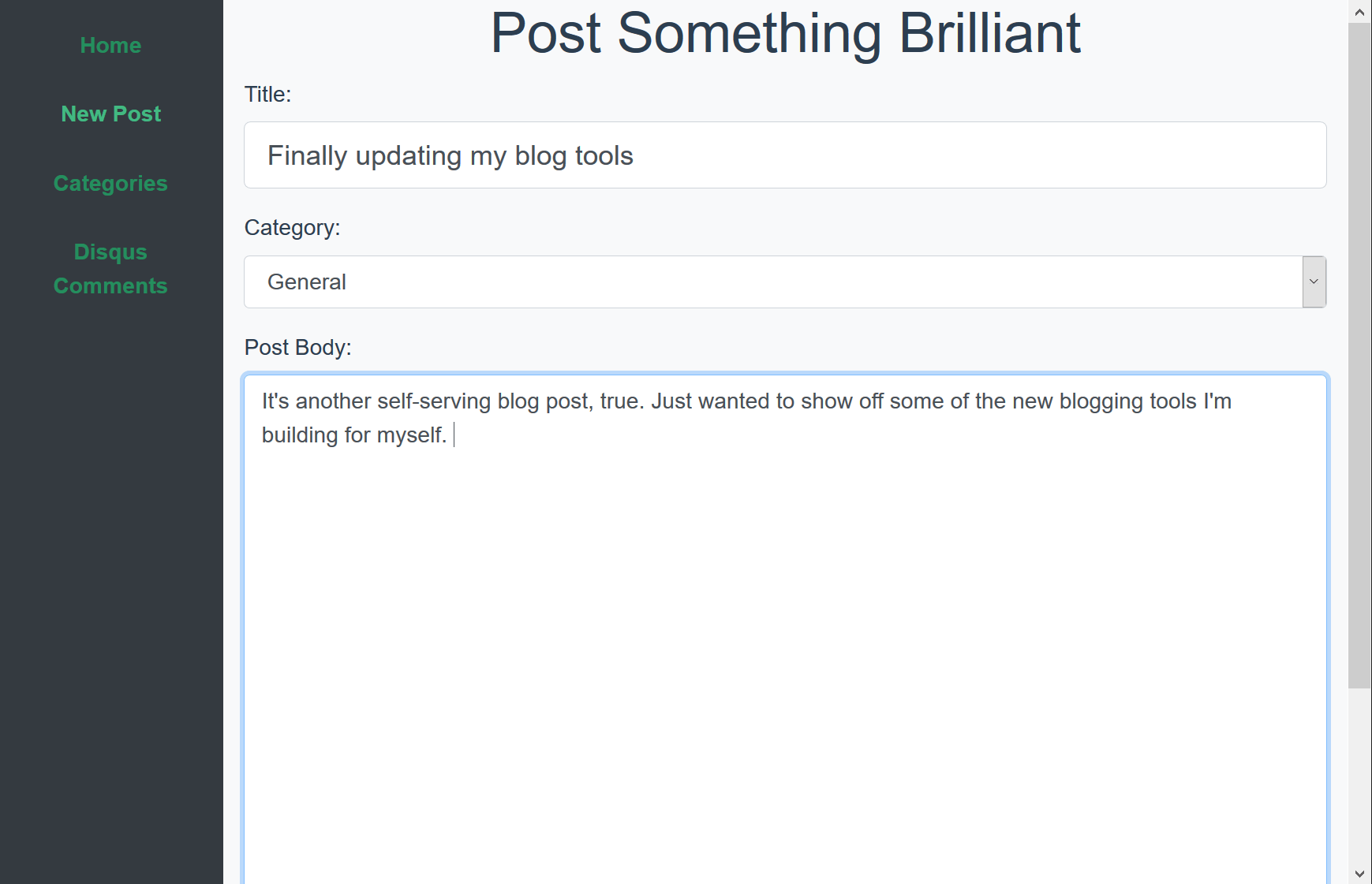
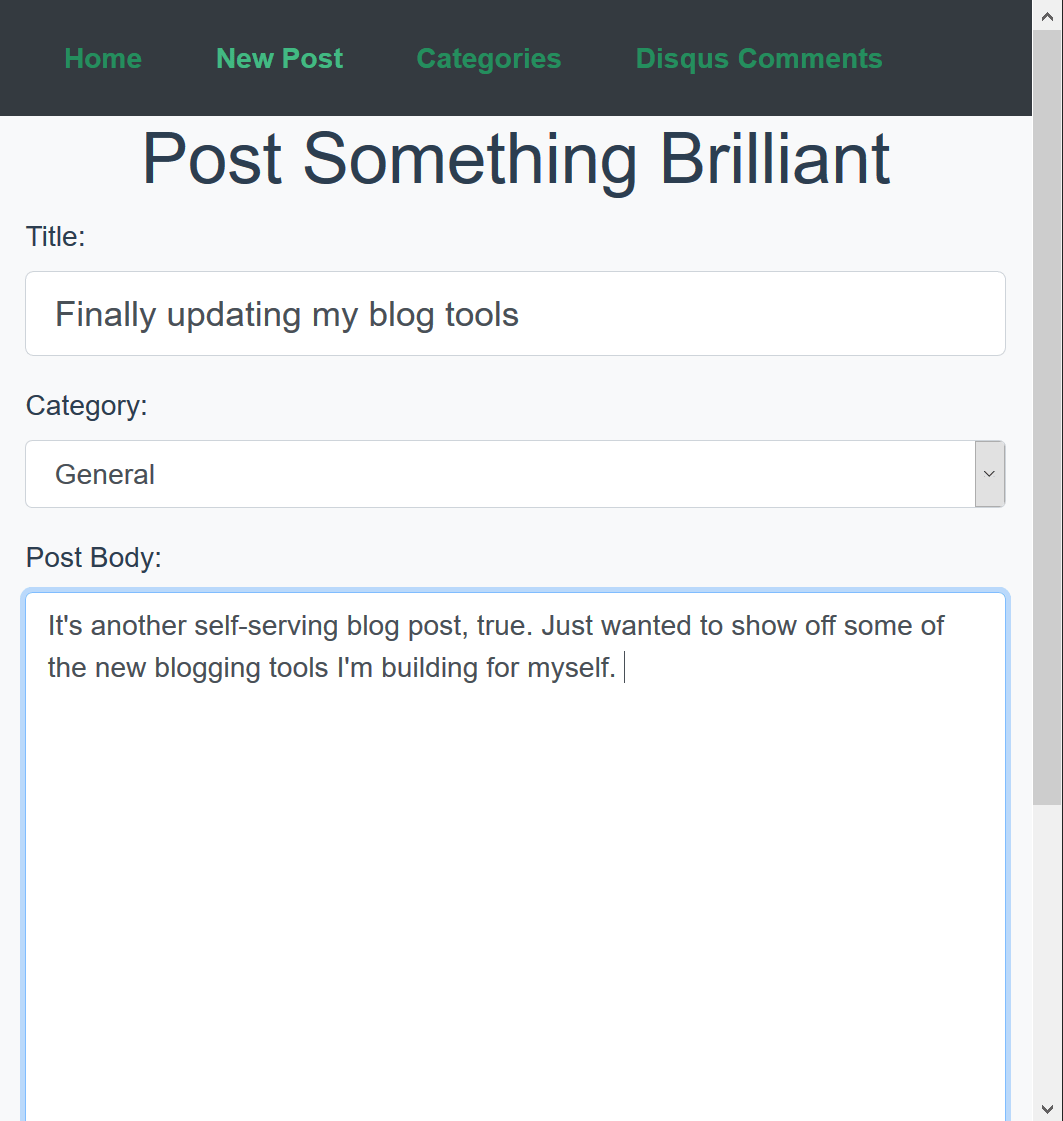
posted under category: Life Events on February 17, 2019 by Nathan
It’s another self-serving blog post, true. Just wanted to show off some of the new blogging tools I’m building for myself. Honestly this is a trial run - I’m crossing my fingers that this will actually post something!
Without further ado, first, something truly hideous. Here’s the bare-minimum thing I’ve been copy-pasting blog posts into.
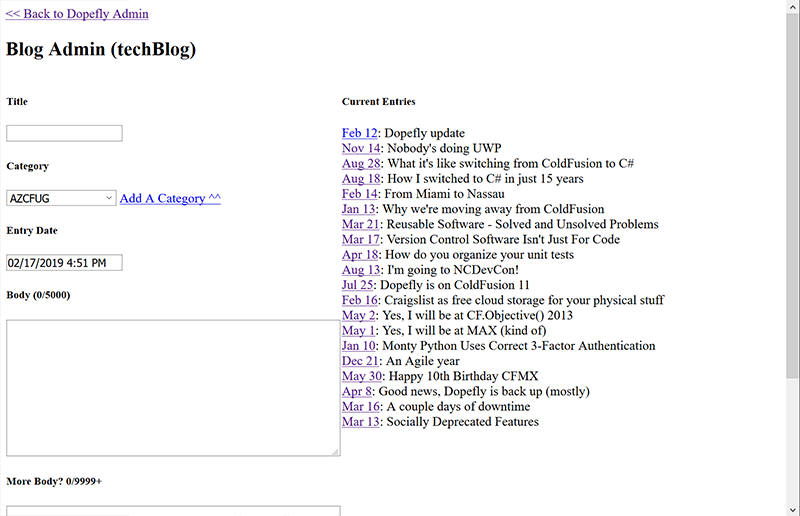
Gross, right? Ok. Now with some default Vue CLI colors and slapping bootstrap on there, it’s a nice, simple, SPA. Here’s what I have today.
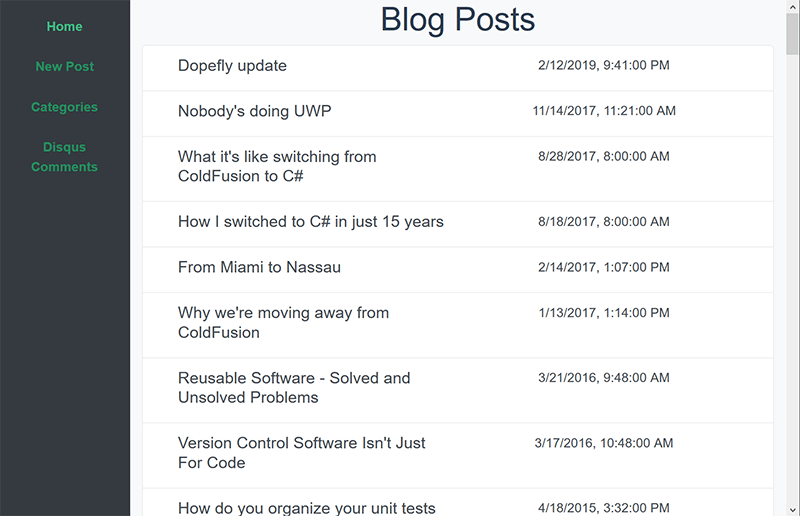
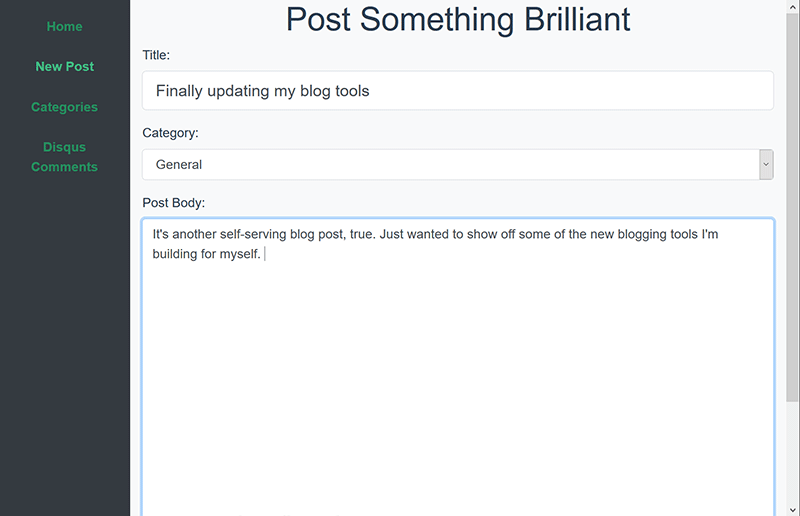
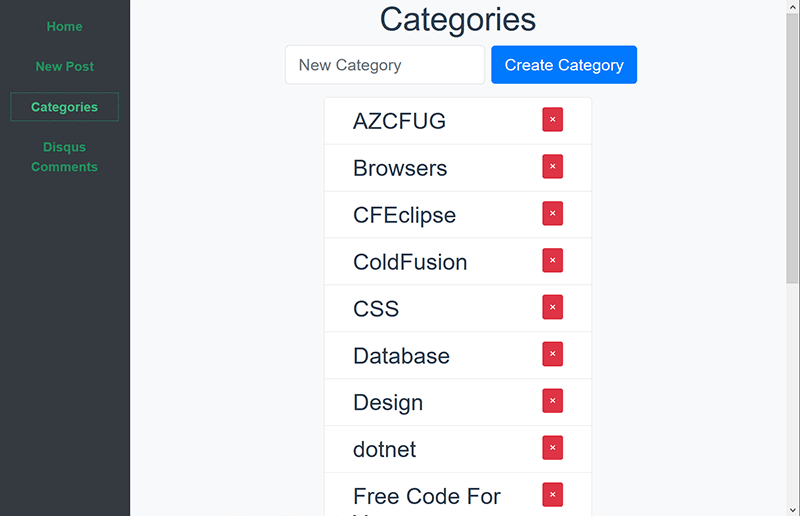
And look, even mobile friendly! At this point with flexbox and responsive frameworks, it’s just too hard not to do that.
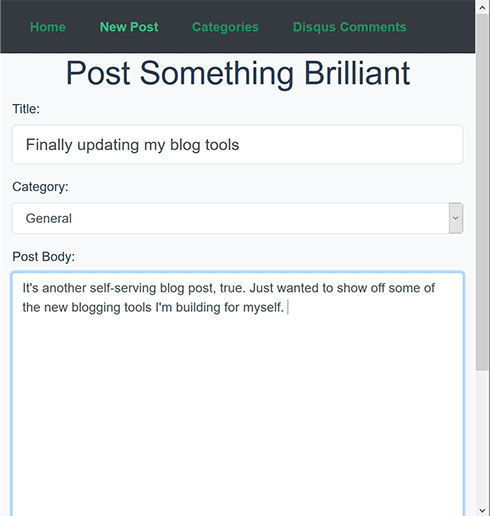
I did say it’s a Vue app! Vue has very quickly become my favorite front-end framework. Yes, I’ve tried the others, and trust me, I’m making a very informed decision here. Vue.js is an incredible, easy-to-start, fun-to-master framework.
For this project, I started with Vue CLI GUI - yes, the graphical interface for the command-line interface for the interface library. Incredible! It generated some boilerplate files so I don’t have to remember how to start with Vuex or Vue-Router. I have Vuex in there to save draft blog posts so I can navigate around and come back. Calling into my APIs running on another port and having the app running in a different URL between local dev and production dopefly.com, at first meant writing CORS rules and still getting lost in the battle, until I found the vue.config.js file. It’s a simple little thing, you just have to know that you need it. Here’s mine:
module.exports = {
publicPath:
process.env.NODE_ENV === "production"
? "/admin/admin-vue/dist/"
: "/",
devServer: {
proxy: "http://dopefly.local/"
}
};
So now it calls local links from the right folder in production, and my APIs are proxied through my locally running web site via Webpack. This works impressively well.
The final piece of setup was to rewrite some of my security framework (I’ve never liked cflogin) and change my old blog admin database access into a handful of simple APIs. The server is Lucee, so the code is dead simple to write and it runs very quickly. The whole thing, including this blog post, took about 8 hours. I’d say it’s a pretty big win for me, personally. It looks good and it runs fast, which is all I ever really wanted.
(Discuss with Disqus!)